Recent work has demonstrated that Generative Adversarial Networks (GANs) can be trained to generate 3D content from
2D image collections, by synthesizing features for neural radiance field rendering. However, most such solutions generate
radiance, with lighting entangled with materials. This results in unrealistic appearance, since lighting cannot be changed and
view-dependent effects such as reflections do not move correctly with the viewpoint. In addition, many methods have difficulty
for full, 360◦ rotations, since they are often designed for mainly front-facing scenes such as faces
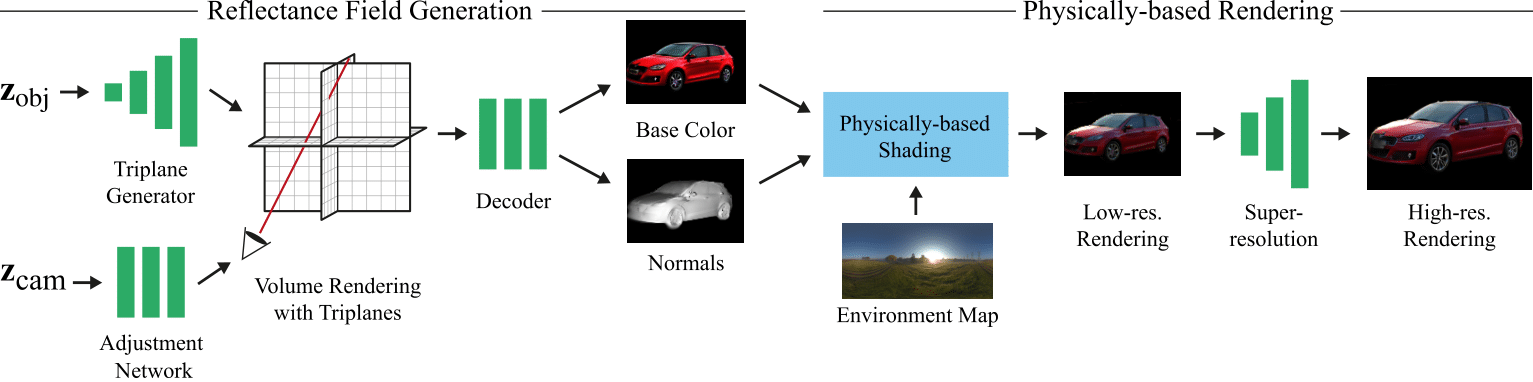
We introduce a new 3D
GAN framework that addresses these shortcomings, allowing multi-view coherent 360◦ viewing and at the same time relighting
for objects with shiny reflections, which we exemplify using a car dataset. The success of our solution stems from three main
contributions. First, we estimate initial camera poses for a dataset of car images, and then learn to refine the distribution of
camera parameters while training the GAN. Second, we propose an efficient Image-Based Lighting model, that we use in a 3D
GAN to generate disentangled reflectance, as opposed to the radiance synthesized in most previous work. The material is used
for physically-based rendering with a dataset of environment maps. Third, we improve the 3D GAN architecture compared to
previous work and design a careful training strategy that allows effective disentanglement.
Our model is the first that generatea variety of 3D cars that are multi-view consistent and that can be relit interactively with any environment map
 2
2  3
3  4
4