
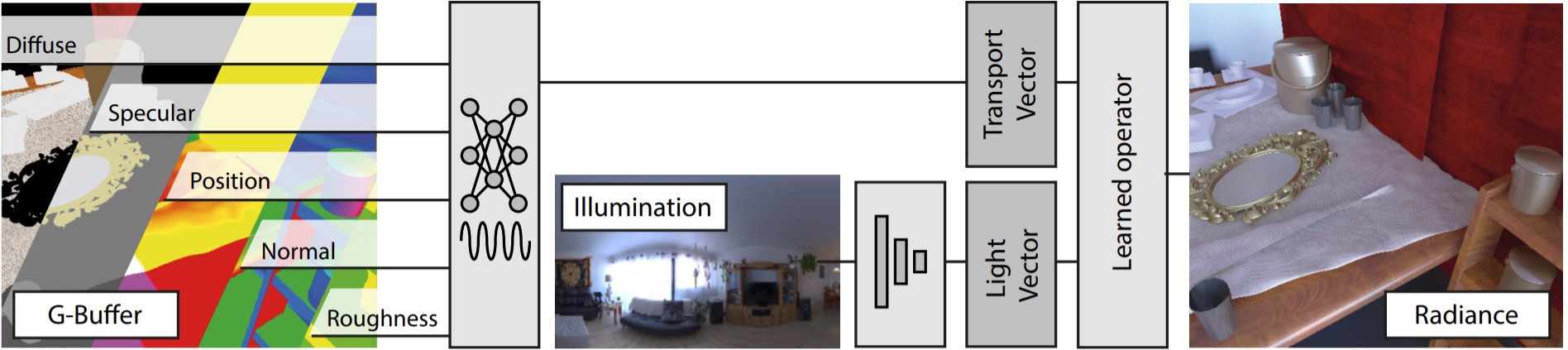
Overview
We examine four architectures of increasing complexity and analogy to PRT. Each proposed framework has the same number of trainable parameters, and takes as input the per-pixel G-buffer information plus a learnt encoding of the environment lighting.
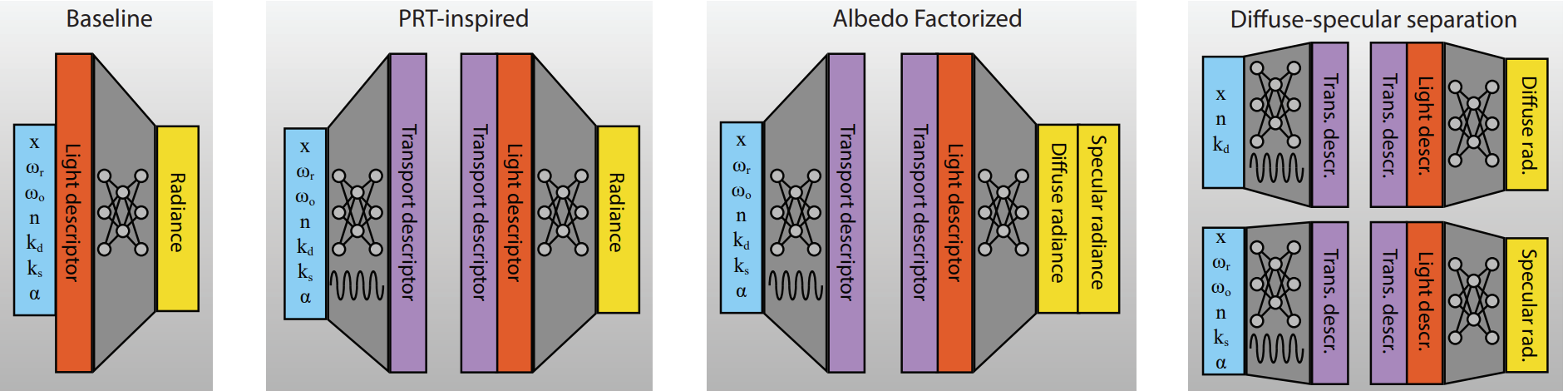
Baseline
The most straightforward architecture is simply a fully-connected network that takes concatenated G-Buffer properties and light codes as input, and directly outputs radiance. However, we do not help the network to disentangle rendering invariants in any way, meaning the learning will converge to a suboptimal average solution. Most noticeably, the shading will appear blurry and baked.
PRT-Inspired
We take inspiration from PRT techniques to modify the flow of information inside the network. Rather than feeding all the inputs into a black box, we train the first half of the network to predict a transport code given the G-Buffer inputs. This code is concatenated to the lighting code and fed to the second half of the network, allowing the learnt processes find better correlations within spatial and angular effects. Visually this translates to sharper highlights and shadows.
Albedo Factorized
We also propose to separate the outputs into diffuse and specular radiance, which are subsequently modulated by the diffuse and specular albedos of the shaded pixel. Here the network does not need to learn the multiplication by the albedos, and can instead focus on producing a quantity closer to irradiance, which is smoother and hence easier to learn.
Diffuse-specular Separation
Finally we also propose to separate the inputs and feed them to two different tracks (of half the size of the previous architectures). The diffuse track only gets diffuse properties of the G-Buffer inputs, while the specular track also receives viewing direction and reflected direction. This allows an internal specialization of each track to the respective appearance, allowing a disentangled learning of view-dependent versus diffuse transport. Visually this results in much more physically correct renderings, with accurate highlights and shadows.
